在 Azure 中,虚拟网络(Virtual Network,简称 VNet)是一种用于托管 Azure 资源的逻辑隔离网络,它提供了一个虚拟网络拓扑结构,用于将 Azure 资源组织在一起并提供安全性和隔离。每个 VNet 都包含一个或多个子网(Subnet),用于将 Azure 资源分配到不同的 IP 子网中。 本文将介绍如何使用 Python…
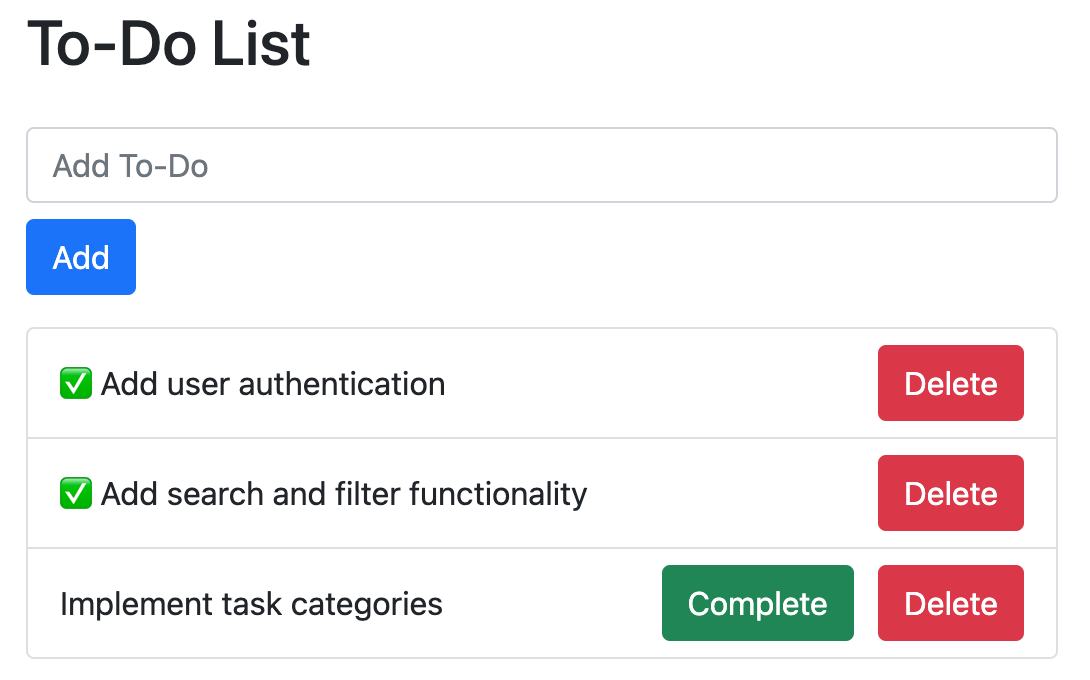
前言 体验 ChatGPT 有段时间了,关于它的代码能力,只是比较粗浅地使用过。比如让它解一道算法题、解释一段代码的含义等。 但它的潜力不止于此,它可以做更多的事情。比如,我们可以让它实现一个 To-Do List Web 应用,像下图这样。 生成初版 To-Do List 和 ChatGPT 对话,最重要的是准确地描述需求。在开源社区中总结了大量…
本周早些时候申请了新版 Bing 的内测资格,昨天终于收到了通过的邮件。 一天的体验之后,我的感受是:当 新版 Bing 具备了 ChatGPT 的聊天能力之后,它的能力不论是对传统搜索引擎,还是 ChatGPT 自身,都将是降维打击 。 百度、谷歌、ChatGPT 与 Bing 的 PK 现在,让我们分别问百度、谷歌、ChatGPT 和 Bing…

前言 Python 中的 list 是一种序列类型,可以存储任意类型的对象,如整数、字符串、元组等。 list 是可变的,也就是说,我们可以在运行时添加、删除或修改 list 中的元素。那么,Python 中的 list 是如何实现和使用的呢?本文将从以下几个方面来介绍: list 的内部结构 list 的动态扩容机制 list 的时间复杂度分析 …
前言 当涉及到演示文稿的自动化、数据可视化或其他需要定制化的任务时,使用Python操作PowerPoint是非常有用的。本文将介绍如何使用Python操作PPT,并提供一些示例代码。 安装Python-pptx库 要使用Python操作PPT,需要安装Python-pptx库。Python-pptx是一个用于创建、更新和修改PowerPoint …
前言 使用Python-docx可以非常方便地读取和写入Word文件,本文将介绍Python-docx的基本用法,并提供一些示例。 安装Python-docx库 Python-docx是一个Python库,可以用于创建和修改Microsoft Word文档。首先需要安装Python-docx库,可以通过以下命令在终端或命令提示符中进行安装: pip…
前言 使用openpyxl可以非常方便地读取和写入Excel文件,本文将介绍openpyxl的基本用法,并提供一些示例。 安装openpyxl库 在开始使用openpyxl库之前,您需要安装它。您可以使用pip命令在命令行或终端中安装openpyxl库,如下所示: pip install openpyxl 打开Excel文件 在使用openpyxl…
本文同步发表于字节话云公众号。 初衷 在某个使用 Python 开发的业务中,涉及到 Terraform 的交互,具体有两个需求: 需要调用 Terraform 的各种命令,以完成对资源的部署、销毁等操作 需要解析 Terraform 配置文件(HCL 语法)的内容,分析里面的组成 对于前者,有一个名为 python-terraform 的开源库,…
本文同步发布于字节话云公众号。 前言 工作中会用到一些内部的 Python 包,自然就需要将 pip 源设置为内部 pypi 服务的 URL。但拿着同一台笔记本回到家中时,要么需要开启 VPN 连接到公司内网,要么需要将 pip 源设置为国内镜像源。 设置 pip 源虽然能用 pip config set global.index-url http…
本文同步发布于字节话云公众号。 前言 前段时间由于将项目使用的某 SDK 进行了升级,在使用 PyCharm+unittest 运行一个用例时,能运行并输出果,却一直无法退出用例。随着排查的深入,发现是此 SDK 中的线程在“作祟”。 用简单的代码复现 简单起见,下面这段代码(Python 2)包含了简单的线程逻辑和一个用例,来复现遇到的问题: #…